

구름EXP는 팀의 작업을 계획하고 공유하고, 회고하고, 보상하는 게이미피케이션 기반의 프로젝트 관리 도구입니다. 이를 기반으로 개인별 학습 목표와 성향에 맞춘 퀘스트를 통해 몰입도 높은 성장을 제공하는 교육용 도구도 서비스 중입니다.
현재 구름EXP는 몽고DB(MongoDB) 6.x를 사용하고 있습니다. 연관된 데이터는 가능한 하나의 Document에 SubDocument로 저장해 Aggregate 연산을 줄이라고 공식 문서에서 권장하지만, 기존 DB의 일부분은 연관 데이터를 별도의 컬렉션으로 분리 저장하게 모델링돼 있었습니다.
이로 인해 유저/그룹 등의 정보를 조회할 때면 2회 이상 lookup을 수행하는 일이 빈번했습니다. 서비스 초기에는 별다른 문제가 되진 않았습니다. 그러나 이 유저/그룹 조회 쿼리 성능 문제는 예기치 않은 순간에 서비스의 발목을 잡기 시작했습니다.
written by Rani
edited by Snow
며칠 전 오후, 갑자기 몽고DB 경고 알람이 울렸습니다. 상점 오픈으로 인해 요청이 일시적으로 늘어나며, 전체적으로 요청에 대한 레이턴시(latency)가 매우 높았습니다. UX에 치명적일 정도였기 때문에 바로 아틀라스(Altas)1 대시보드를 열고 문제 쿼리를 추적했습니다. 원인을 파악하기 위해 아틀라스에서 실행 시간, Num Yields2 등 여러 지표를 우선 확인했습니다.
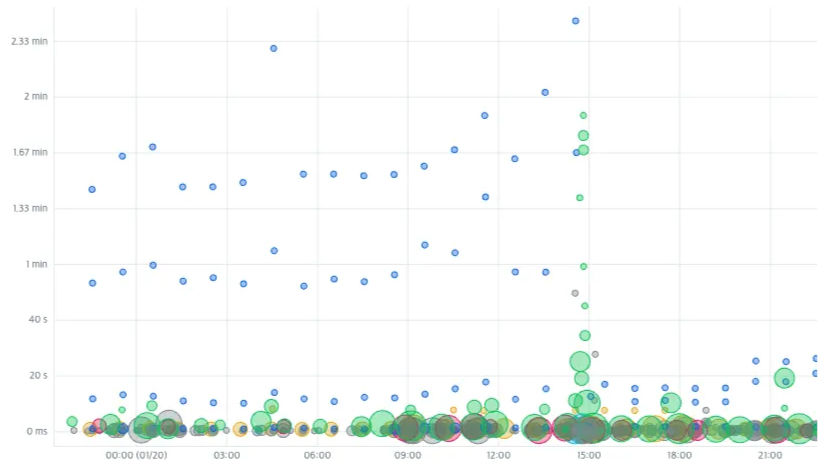
실행 시간이 대기권을 뚫고 우주로 치솟고 있습니다. 잠시 흐르는 눈물을 닦고 원인을 찾았습니다.
문제는 그룹/그룹 유저 컬렉션에서 발생했습니다. 최악의 경우 쿼리 실행에 약 2m(분)이나 걸렸습니다. 2s(초)가 아니라 2m입니다. 오타라면 좋았겠지만 오타는 아니었습니다.
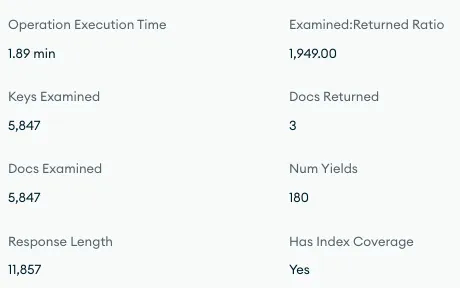
고작 문서 3개 반환에 너무 많은 문서를 스캔하고, Num Yields 횟수도 지나치게 높았습니다. 실행 시간이 길어지며 다른 작업에 리소스를 양보하는 일이 계속 벌어지면서 더 느려지는 ’악의 굴레’에 빠진 듯 했습니다.
문제가 발생한 시간대에 가장 레이턴시가 높은 쿼리를 살펴보니, 상위에는 한결같이 하나의 쿼리가 있었습니다.
아틀라스 쿼리 인사이트(Atlas Query Insights)3에 기록된 슬로우 쿼리(Slow Query)의 $project 값으로 서버 코드상에서 어디가 문제인지 파악했습니다. 유저가 가입한 그룹 목록과 함께 그룹 내 멤버 목록, 추가 유저 정보를 한 번에 불러오는 부분이 문제였습니다.

해당 시간대에 쿼리는 8.46k회 수행했는데, 총 실행 시간은 거의 7시간이었습니다. 평균 2.5초 이상 걸렸으니, 매우 오래 걸렸습니다. 🥹 당연히 너무 느리다는 고객 문의가 폭발했습니다.
범인은 바로 첫 번째 중첩 $lookup
구름EXP는 그룹원이라는 의미의 ‘멤버’ 정보와 유저 자체 정보, 조직원 정보를 별도의 컬렉션으로 저장하고 있습니다.
문제의 원인으로 추정되는 쿼리는 멤버 정보뿐 아니라, 멤버의 추가 정보를 가져오기 위해 중첩 $lookup을 사용하고 있었습니다.
{
"type": "command",
"command": {
"aggregate": "{{그룹 컬렉션}}",
"pipeline": [
{
"$match": { // ❶
"organizationId": "{{조직ID}}"
}
},
{
"$lookup": { // ❷
"from": "{{그룹 멤버 컬렉션}}",
"localField": "id",
"foreignField": "groupId",
"pipeline": [
{
"$lookup": {
"from": "{{조직 유저 컬렉션}}",
"localField": "userId",
"foreignField": "userId",
"let": {
"organizationId": "$organizationId"
},
"pipeline": [
{
"$match": {
"$expr": {
"$eq": [
"$organizationId",
"$$organizationId"
]
}
}
}
],
"as": "users"
}
},
{
"$unwind": "$users"
},
{
"$project": {
//...필요한 값만 추출
}
}
],
"as": "members"
}
},
{
"$lookup": {
"from": "{{그룹 멤버 컬렉션}}",
"localField": "id",
"foreignField": "groupId",
"pipeline": [
{
"$match": { // ❸
"$expr": {
"$eq": [
"$userId",
"{{유저ID}}"
]
}
}
},
{
"$project": {
//...필요한 값만 추출
}
}
],
"as": "user"
}
},
{
"$unwind": "$user"
},
],
},
//...
}$project, $unwind 등 부가적인 연산을 제외하면 이 쿼리는 다음 동작을 수행합니다.
쿼리 동작 흐름
❶ 특정 조직에 속한 그룹을 $match로 필터링
❷ 중첩된 $lookup을 사용해 각 그룹에 속한 멤버 정보와 각 멤버의 추가 유저 정보 조회
❸ ❷ 결과에서 추가 $lookup을 통해 특정 유저의 멤버 정보 필터링
결과적으로 한 유저가 소속된 그룹을 반환하는데, 이때 그룹 내 멤버 정보 목록이 유저 정보와 함께 반환됩니다.
자, 그럼 여기에 어떤 문제가 있는지 살펴보겠습니다.
실행 계획으로 자세히 분석하기
그룹 컬렉션으로부터 aggregate를 시작하면 lookup 없이 유저가 속한 그룹의 정보를 바로 필터링할 수 없습니다.
그래서 쿼리 동작 흐름 ❶에서는 $match 연산으로 특정 조직에 속한 모든 그룹 정보를 반환받고, 이 전체 그룹(결과)이 다음 ❷($lookup)로 넘어갑니다.
즉, 유저가 속하지 않은 그룹의 멤버에 대해서도 불필요한 $lookup을 수행하는거죠. 조회 자체는 인덱스에 의해 빠르게 수행되지만, 부담이 큰 다음 단계로 많은 문서가 반환되는 게 문제의 원인️️이었습니다.
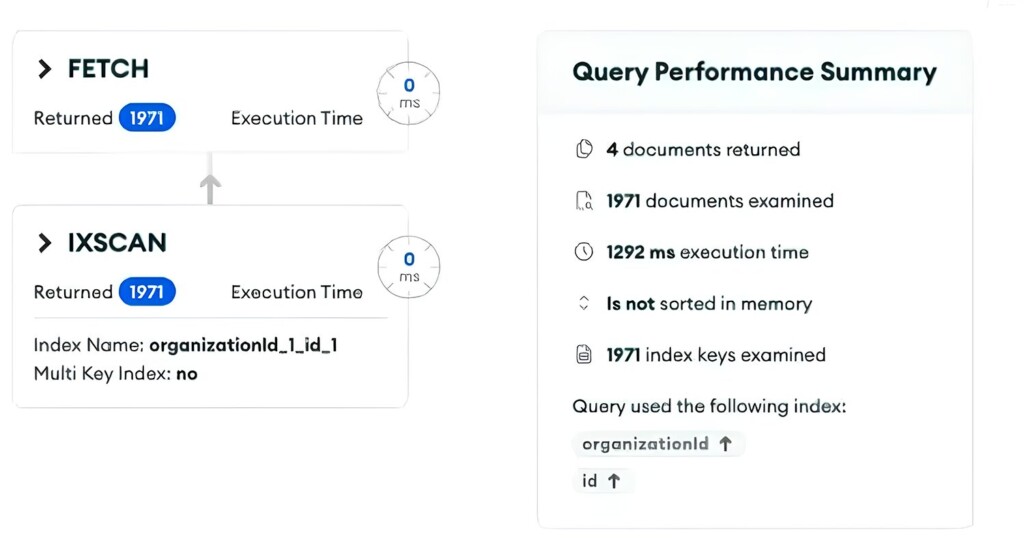
결과로 반환된 문서는 4개뿐인데, 총 1971개의 문서를 거쳤고 실행 시간은 1,292ms이었습니다. 이제 자세한 실행 계획을 확인해 봅시다.
{
"$lookup": {
"from": "{{그룹 유저 컬렉션}}",
"as": "members",
"localField": "id",
"foreignField": "groupId",
"let": {},
"pipeline": [
{
"$lookup": {
"from": "organizationUsers",
"localField": "userId",
"foreignField": "userId",
"let": {
"organizationId": "$organizationId"
},
"pipeline": [
{
"$match": {
"$expr": {
"$eq": [
"$organizationId",
"$$organizationId"
]
}
}
}
],
"as": "users"
}
},
{ "$unwind": "$users" },
{
"$project": {
// ... 필요한 값 추출
}
}
]
},
// 중첩된 lookup 파이프라인에서 약 0.9s 소요함
// 처리 결과 1971개로, 많은 문서가 aggregate됨
"totalDocsExamined": 5369,
"totalKeysExamined": 5369,
"collectionScans": 0,
"indexesUsed": [
"groupId_1_userId_1",
"organizationId_1_userId_1"
],
"nReturned": 1971,
"executionTimeMillisEstimate": 916
},처음 중첩 $lookup을 수행하는 부분의 실행 계획입니다.
❶ 그림 4)의 FETCH 단계에서는 인덱스를 통해 매우 빠르게 결과를 반환하지만, 1,971개의 문서가 반환됨
❷ 5,369개 문서가 스캔됨
문제가 되는 건 $lookup 실행 계획 ❶입니다. executionTimeMillisEstimate 값을 보면 lookup 처리 과정에 무려 916ms가 소요됩니다. 😱 쿼리 성능에 악영향을 끼치는 구간입니다.
검사한 총 문서는 5,369개, 반환된 문서(nReturned)는 1,971개로, $lookup을 한 전체 문서의 37%만이 필요한 문서였습니다. 잘 필터링하면 $lookup에 포함되는 문서 수를 줄여 성능을 개선할 수 있겠네요. 👍
이제 중첩 $lookup 뒤에 있는 또 다른 $lookup 연산을 살펴보겠습니다.
{
"$lookup": {
"from": "{{그룹 멤버 컬렉션}}",
"as": "user",
"localField": "id",
"foreignField": "groupId",
"let": {},
"pipeline": [
{
"$match": {
"$expr": {
"$eq": [
"$userId",
"{{유저ID}}"
]
}
}
},
{
"$project": {
// ... 필요한 값 추출
}
}
],
// 아래 unwind단계에서 유저가 매칭되지 않는 (유저가 속하지 않은) 그룹 정보는 제거됨
"unwinding": {
"preserveNullAndEmptyArrays": false
}
},
// 두 번째 룩업에서 요청한 user의 정보를 추가함
"totalDocsExamined": 4,
"totalKeysExamined": 4,
"collectionScans": 0,
"indexesUsed": ["groupId_1_userId_1"],
"nReturned": 4,
// 1269(누적시간) - 916(이전 파이프라인) = 353ms 소요
"executionTimeMillisEstimate": 1269
},앞서 반환된 1,971개 문서에 유저 정보를 $lookup합니다. 이때 $unwind로 매칭되는 유저가 없는 경우 제거되기 때문에 유저가 속한 그룹 목록만 반환됩니다.
앞선 $match 단계(쿼리 동작 흐름 ❶)에서 많이 걸러지지 못한 상황에서 $lookup을 수행한 뒤, 필요한 정보를 필터링합니다.
누적 실행 시간 추정값이 1,269ms인 것으로 볼 때 이전 파이프라인에서 소요된 916ms를 제외하면, 여기에서 353ms가 걸렸습니다. 예시로 든 유저는 4개의 그룹에 속해있으므로, nReturned는 4입니다.
그외의 연산이 포함되면서 최종적으로 쿼리 실행에는 1,292ms가 걸렸습니다.
이전에는 왜 문제가 없었을까? 🤔
원래도 성능이 좋은 쿼리는 아니었지만, 갑자기 성능 문제가 발생하기 시작한 계기는 있었습니다.
바로 ‘개인 그룹’이 추가되면서, 매우 많은 그룹이 생성된 일이었습니다. 한순간에 가장 많이 사용되는 컬렉션에 많은 데이터가 추가되며 서비스 전체에 성능 문제가 발생한 것입니다.
쿼리 개선하기
① 쿼리 실행 과정에서 ❷ $lookup 단계로 넘어가는 문서 수를 줄이기 위해, 그룹 컬렉션이 아닌 그룹 유저 컬렉션에서 aggregate를 합니다.
- 이 경우, 처음부터
userId값으로 불필요한 문서가 전부 걸러집니다.
② aggregate 연산 시 다수의 $lookup을 사용하지 않게 하고 쿼리도 쪼갭니다.
- 앞선 쿼리로도 충분한 경우가 많으므로, 이 경우 후속 쿼리를 타지 않도록 합니다.
- 쿼리를 쪼개고 일부 연산 작업을 애플리케이션 서버에 위임하면, 단일 쿼리에 대한 부담을 줄이고,
Num Yield가 커지는 것을 최소화할 수 있습니다.
개선 방안 ①에서 최소한의 문서만 남겨지므로, 쿼리를 쪼개 매핑하는 작업을 애플리케이션 서버에 위임하더라도 큰 부담이 없습니다.
개선 후
aggregate 파이프라인에 하나로 묶여 있던 [유저의 그룹 조회 쿼리], [그룹 멤버 + 추가 정보 조회 쿼리]를 분리했습니다.
유저의 그룹 조회 쿼리

[
{
$match: {
$expr: {
// $lookup수행 전에 $match연산으로 최소한의 데이터만 필터링함
$and: [
{
$eq: [
"$organizationId",
"{{조직ID}}"
]
},
{
$eq: [
"$userId",
"{{유저ID}}"
]
}
]
}
}
},
{
$project:
{
groupId: 1,
_id: 0
}
},
// 실제로 필요한 것은 그룹 멤버가 아닌 그룹 목록이므로, 그룹 정보를 lookup함
{
$lookup:
{
from: "{{그룹 컬렉션}}",
localField: "groupId",
foreignField: "id",
as: "group"
}
},
{
$project:
{
group: 1
}
},
{
$unwind:
"$group"
},
// 루트를 그룹 멤버 정보가 아닌 그룹 정보로 치환함
{
$replaceRoot:
{
newRoot: {
$mergeObjects: ["$group", "$$ROOT"]
}
}
},
{
$project: {
group: 0
}
}
]유저의 그룹 조회 쿼리 수행 결과, 유저가 속한 그룹 목록 정보가 반환됩니다. 최상단 내용을 그룹 유저가 아닌 그룹 정보로 만들기 위해 $replaceRoot를 수행합니다.
그룹 컬렉션에서 aggregate를 하는 것보다는 그룹 유저 컬렉션에서 수행하고 $replaceRoot하는 것이 더 합리적이기 때문입니다.
정말 그런지 변경된 유저의 그룹 조회 쿼리의 실행 계획을 살펴보겠습니다. 눈여겨볼 부분은 다음 내용입니다.
{
"nReturned": 4, // 해당 스테이지에서 반환된 문서 수
"executionTimeMillisEstimate": 4, // 추정 수행시간
"keysExamined": 2174, // 인덱스 스캔시 검사한 문서 수
"keyPattern": {
"organizationId": 1,
"groupId": 1,
"userId": 1
},
"indexName": "organizationId_1_groupId_1_userId_1", // 사용된 인덱스
}개선 전 쿼리에서는 유저가 속한 그룹 정보를 가져오는 데 많은 시간이 소요되었으나, aggregate 시작점을 변경한 결과, 4ms만에 조회를 마쳤습니다.
성능을 개선할 수 있는 지점이 하나 더 있습니다. 혹시 찾았나요?
추가 개선사항: 복합 인덱스 추가
실행 계획의 indexName에서 알아챘겠지만, 이 쿼리는 조직ID + 그룹ID + 유저ID 복합 인덱스로 스캔합니다. 반환되는 문서(nReturned)는 4개이지만, 인덱스 스캔한 문서(keysExamined)는 2174개입니다.
우리는 조직ID + 유저ID 조건으로 필터링하므로, 이 경우 복합 인덱스의 중간에 있는 그룹ID로 인해 이상적으로 인덱스를 사용하지 못합니다. 그룹 멤버 컬렉션에 조직ID + 유저ID 복합 인덱스를 추가하면 탐색을 최적화해 탐색 범위를 줄일 수 있습니다.
복합 인덱스를 추가로 걸면 keysExamined도 4로 줄어들 것입니다. 이전 쿼리와 비교하면 실행 시간뿐 아니라 스캔 및 처리하는 문서 수도 압도적으로 줄어들었습니다.
결과적으로 근본적인 목적인 ‘유저가 속한 그룹을 조회하기’만 수행할 경우 5ms만에 필요한 정보를 반환받을 수 있었습니다.
그룹에 속한 멤버들 정보까지 반환하는 경우
그룹에 속한 멤버 정보까지 반환하는 쿼리를 살펴봅시다. 앞서 작성한 쿼리를 이용합니다. 개선 전 쿼리와 개선 후 쿼리를 비교하면, 동작 자체는 같으나 순서가 다릅니다.
[개선 전]
- 우선 모든 멤버 정보를
$lookup - 유저가 속한 그룹만 필터링
[개선 후]
- 유저가 속한 그룹만 필터링
- 별도의 분리된 쿼리로 각 그룹에 속한 멤버 정보
$lookup - 이전 두 쿼리 수행 결과를 매핑
우선 유저가 속한 그룹의 정보를 가져온 뒤, $in 쿼리로 이 그룹에 속한 멤버 정보를 조회합니다. 결과로 그룹 멤버 목록이 반환됩니다.
⚠️$in사용 시 주의사항$in쿼리의 경우 배열 크기가 커지면 성능 저하가 발생할 수 있습니다.
가입한 그룹이 가장 많은 경우와 일반적인 경우의 개수를 확인해 $in 쿼리 수행에 문제가 있을지 확인했습니다. 그 결과 연산에 필요한 리소스는 미미하다 판단되어 $in 쿼리를 사용했습니다.
이제 다음과 같이 멤버의 정보까지 반환하는 후속 쿼리를 작성합니다.
[
{
$match: {
$expr: {
$and: [
{
$eq: [
"$organizationId",
"{{조직ID}}"
]
},
{
$in: [
"$groupId",
[
...앞선 쿼리에서 반환된 그룹의 ID들
]
]
}
]
}
}
},
{
$lookup: {
from: "{{조직 유저 컬렉션}}",
localField: "userId",
foreignField: "userId",
let: {
organizationId: "$organizationId"
},
pipeline: [
{
$match: {
$expr: {
$eq: [
"$organizationId",
"$$organizationId"
]
}
}
}
],
as: "userInfo"
}
},
{
$unwind: "$userInfo"
},
{
$project: {
// ...필요한 값만 추출
}
},
// 그룹ID를 기준으로 그룹핑
{
$group: {
_id: "$groupId",
count: {
$sum: 1
},
documents: {
$push: "$$ROOT"
}
}
},
{
$addFields: {
groupId: "$_id" // Rename _id to groupId
}
},
{
$project: {
groupId: "$_id",
members: "$documents", // members에 그룹핑된 멤버 목록 삽입
_id: 0
}
}
]파이프라인 내 작업 수만 보면 더 많아졌지만, 작업에 드는 비용은 더 줄어들었습니다. 이 쿼리를 수행하면 코드 1과 같이 그룹ID에 따라 그룹핑된 멤버 목록을 반환합니다.
{
"groupId": {{그룹ID}},
"members": [...그룹 멤버 목록}}
}쿼리 실행 계획을 살펴보겠습니다.
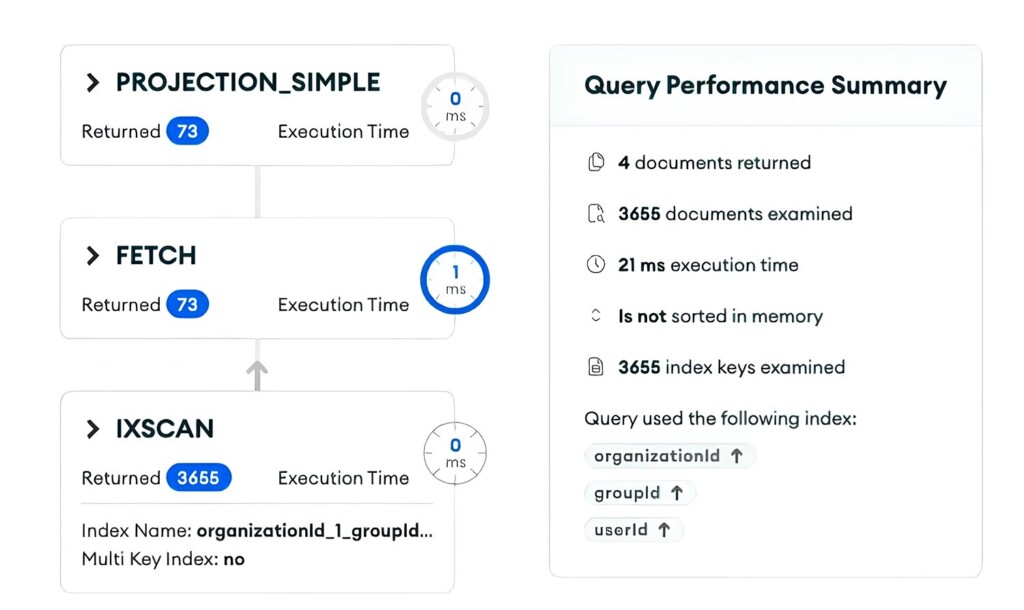
쿼리 실행 계획 전체에서 중요한 부분만 뽑아 확인하겠습니다.
// input stage
{
"nReturned": 3655,
"keysExamined": 3655,
"executionTimeMillisEstimate": 1,
}앞서 본 것처럼 전체 반환 수(nReturned)에 비해 많은 문서를 스캔하고 있습니다. 복합 인덱스 순서에는 문제가 없으므로 $in 쿼리가 원인이라고 추측됩니다.
스캔 수는 많아졌으나 적절한 인덱스를 사용해 실행 시간은 1ms에 불과합니다. $in 쿼리를 쓰는 데에는 문제는 없어 보입니다.
input stage 밖 전체 내용을 보면, 조회와 더불어 $project 등을 포함한 총 실행 결과는 다음과 같습니다.
"nReturned": 73,
"executionTimeMillis": 21,
"totalKeysExamined": 3655,두 번째 쿼리는 총 21ms 시간이 걸렸습니다. 내가 속한 그룹 조회 및 각 그룹의 멤버 목록을 조회하는 데 두 쿼리를 합쳐 대략 5ms + 21ms가 소요됐습니다.
이제 서버에서 각 그룹에 멤버 목록 매핑 과정만 하면 됩니다! 이 연산은 시간 복잡도가 대단히 크지 않으므로, 쿼리 실행 시간에 큰 영향은 없을 겁니다. 모두 합쳐 대략 30ms + @로 추정해도 되겠네요. 기존 1,287ms에 비교해서는 비약적으로 개선됐네요.
쿼리 성능 개선에 따른 효과 📈
이 글에서 다룬 쿼리가 사용되는 부분은 의외로 여러 곳이었습니다. 전부 꼼꼼하게 확인해 보니, 기존 파이프라인을 재사용하면서 불필요한 정보를 lookup하는 경우가 많았습니다. 😱
조회하도록 고치면서 자연스레 여러 API에 걸쳐 전반적인 성능 개선이 이루어졌습니다.
aggregate 순서 변경과 쿼리 쪼개기로, 개선 전 쿼리에서 전체 멤버를 받아야 하는 상황에서도 인덱스 추가, 캐싱 없이 실행 시간을 1287ms에서 약 30ms로 단축할 수 있었습니다.
이번 개선으로, 쿼리를 분리함으로써 정말 필요한 정보만
문제가 된 컬렉션 관련 쿼리의 성능 문제는 내부에서 이미 알고 있는 이슈였으나, 갑자기 레이턴시가 심해지는 바람에 한 번 정리하게 되었습니다.
성능 최적화를 하면서 다음과 같은 깨달음도 얻었습니다.
- 파이프라인은 동일한 역할을 한다고 함부로 재사용하지 말자
- 기획에 변경사항이 발생하여 많은 데이터가 삽입되는 경우, 기존 쿼리 성능에 영향은 없는지 확인하자!
고객 문의가 일시적으로 증가했지만 평소에 관심이 많던 성능 개선 작업을 할 수 있었고, 좋은 쿼리에 대해서 고민하는 계기가 되었습니다. 😊



