

GenAI SQD의 Jhin입니다. 이 글은 ‘프롬프트 엔지니어링’을 개발자, 비개발자 모두 이해할 수 있도록 최대한 쉬운 언어로, 여러 예시를 들어서 설명합니다. LLM(Large Language Model), 더 정확하게는 챗GPT(ChatGPT)를 쓰기 위해 알아야 할 프롬프트 엔지니어링의 기초라고 할 수 있겠네요.
‘문화’는 한 사회에서 공통적으로 나타나는 주요한 행동 양식을 말합니다. 문화를 만들기 위해서는 구성원을 설득하고, 생각의 변화를 유도하고, 그 변화가 행동으로까지 이어지게 해야 합니다. 규칙이 아닌 자율적으로 문화가 형성되게 하는 건 그래서 쉽지 않습니다.
기술 블로그를 만들 때 고민했던 지점이 바로 그 점이었습니다. 사내 개발 문화와 서비스를 외부에 알리고, 글을 씀으로써 서로의 경험과 노하우를 사내에 공유하고, 함께 성장한다는 ‘기술 블로그 취지’를 어떻게 살리며 우리의 문화로 정착되게 할지가 고민이었습니다. 글쓰기 동호회를 만들기도, 먼저 글쓰기를 제안하기도 하고, 직접 쓰기도 한 것이 이제는 제법 쌓였습니다. 1년이 되어갈 때 쯤에는 기술 블로그에 ‘기고’하겠다고 먼저 나서는 분도 생겼습니다.
올해 초에는 사내 기술 세미나 ‘STRIDE’도 시작했습니다. 사내 기술 세미나의 여러 이야기를 기술 블로그에 옮기겠다는 생각에서였습니다. 조직별로 사일로화 된 벽을 허물고 서로의 경험과 지식을 공유하기 위해서는 글뿐 아니라 발표도 필요했습니다.
올해 초 시작했던 구름 사내 기술 세미나 STRIDE는 벌써 6회를 맞았습니다. 그리고 애초에 마음먹었던 대로, 그 이야기 중 하나를 기술 블로그에 옮겨 여러분에게 들려드리겠습니다.
editor Snow DevRel Manager.
☁️ 이 글은 구름 사내 기술 세미나 STRIDE에서 GenAI SQD의 Jhin이 발표한 내용을 재편집한 내용임을 밝힙니다. |
GenAI SQD의 Jhin입니다. 이 글은 ‘프롬프트 엔지니어링’을 개발자, 비개발자 모두 이해할 수 있도록 최대한 쉬운 언어로, 여러 예시를 들어서 설명합니다. LLM(Large Language Model), 더 정확하게는 챗GPT(ChatGPT)를 쓰기 위해 알아야 할 프롬프트 엔지니어링의 기초라고 할 수 있겠네요.
written by Jhin
AI란?
LLM은 AI(Artificaial Intelligence)의 일종입니다. 우리가 일반적으로 ‘인공지능’이라고 말하는 AI는 사람이 사고하는 것을 모방한 인공지능이라고 할 수 있습니다. 더 정확하게 말하면 인간의 학습 능력, 추론 능력, 지각 능력 같은 지적 능력을 인공적으로 구현하는 컴퓨터 과학의 세부 분야 중 하나입니다.
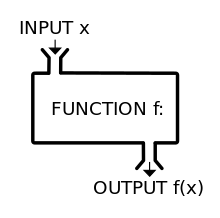
AI에는 입력값이 있습니다. 그 입력값은 데이터가 될 수도 있고 자연어가 될 수도 있죠. 마우스 클릭 같은 사람의 행동 패턴이나 이미지가 될 수도 있습니다. 이러한 입력값이 들어왔을 때 AI는 이를 학습하고 추론하고 지각을 합니다. AI 모델에 입력값을 넣었을 때 적절한 출력값이 나오는 것. 이것이 AI입니다.
중·고등학교 때 배운 함수 방정식을 떠올리면 이해하기 쉬운데요. 함수는 주어진 x 값(입력)을 가지고 y 값(출력)을 맞추는 겁니다. ‘예측한다’, 혹은 ‘찾는다’라고 하죠.
LLM이란?
LLM은 Large Language Model의 약자로, 거대 언어 모델을 말합니다. 그렇다면 언어 모델은 무엇일까요? 언어 모델은 자연어에 대한 확률 모델입니다. 말이 조금 어렵죠? 자연어의 확률 분포를 출력값 그러니까 결괏값으로 내뱉는 모델이라고 할 수 있습니다.
대표적인 LLM이 바로 챗GPT입니다. 질문하면 답을 주죠. 그런데 이게 확률 모델이랑 무슨 상관이 있을까요?
확률 모델
확률 모델은 확률 변수가 특정 값을 가질 확률을 나타내는 함수입니다. 예를 들어 쉽게 설명할게요.
주사위를 던지는 것이 입력값이라고 합시다. 주사위를 던졌을 때 출력값으로 무엇이 나올지는 아무도 모릅니다. 우리가 알 수 있는 것은 단지, 1에서부터 6까지의 값이 각각 6분의 1 확률로 나온다는 것 정도죠. 확률 모델은 이러한 주사위와 같습니다.
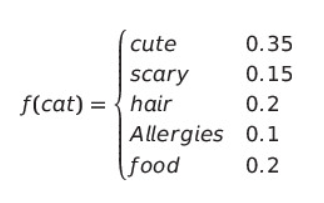
어떤 언어 모델에게 ‘cat’이라는 단어를 주고(입력), cat 뒤에는 어떤 단어가 올지 묻는다고 가정해 보죠. 챗GPT나 클로드(Claude)와 같은 LLM은 “다음에는 이 단어가 올거야”라고 알려주는 게 아니라 “cute는 0.35, 정확하게는 35%의 확률로 오고, scary는 15%의 확률, hair는 20%의 확률, allergies는 10%의 확률, food는 20%의 확률을 올 거야”처럼 ‘확률’로 답합니다. 확률적 통계에 의해 이중 한 단어가 선택되어 출력되는거죠. 모든 단어에 대해 이러한 과정을 반복해 사람이 쓴 것 같은 자연스러운 문장을 만들어 냅니다.
프롬프트 엔지니어링이란?
프롬프트 엔지니어링은 LLM이 맥락 없이 아무 자연어나 생성하는 것이 아니라 우리가 원하는 결과를 끄집어 내게 하는 기술입니다.

근데, 여기서 ‘프롬프트’란 뭘까요? 혹시 들어봤나요?
프롬프트는 방송에서 아나운서가 방송을 진행하기 수월하도록 보여주는 대사를 말합니다. 이를 띄어주는 기기를 프롬프터라고 하죠. 프롬프트 엔지니어링은 LLM이 특정 작업을 수행할 수 있도록, 방송에서 아나운서에게 해야 할 말을 알려주는 프롬프트처럼 LLM에게 요청하는 자연어 텍스트를 말합니다.
ChatGPT와의 대화를 예로 들어보겠습니다. “오늘의 운세를 봐줘”라고 챗GPT에게 묻자, 챗GPT는 “물론, 오늘의 운세를 알려드리겠습니다…”라고 답했습니다. 여기서 “오늘의 운세를 봐줘”가 바로 프롬프트죠.

그렇다면 프롬프트 엔지니어링은 무엇일가요? 프롬프트를 굳이 엔지니어링(공업의 이론, 기술, 생산 따위를 체계적으로 연구하는 학문)까지 할 게 있을까요?
바로 앞 예시처럼 챗GPT에게 “오늘의 운세를 봐줘”라고 말해도 운세를 알려주기는 합니다. 그러나 다른 운세 서비스와 다르게 내 이름도, 생일도 묻지 않고 그럴듯한 답을 생성해 냈을 뿐이죠.
운세를 정확히 보기 위해서는 사람의 이름, 나이, 태어난 시간, 태어난 날자, 요일과 같은 정보가 필요합니다. 이러한 내용도 프롬프트에 함께 전달했어야 하죠.
이 모든 정보를 프롬프트 한 줄에 다 나열해 전달해도 되긴 합니다. 여기서 더 나아가 어떻게 프롬프트를 작성하면 좀 더 나은 결과를, 좀 더 효과적으로 프롬프트를 작성할 수 있을까에서 시작된 게 바로 ‘프롬프트 엔지니어링’입니다.
프롬프트 작성의 기초 팁
앤드류 응(Andrew Ng)은 지금의 AI 혁명의 시작이 된 딥러닝 분야에서 괄목할 만한 성과를 낸 과학자 중 한 명입니다. 구글 산하의 구글 브레인 설립자의 하나로, 인공지능 지식의 대중화에도 힘쓰고 있죠.

앤드류 응은 프롬프트 엔지니어링과 관련해서 다음과 같이 팁을 공유했었습니다.
- 구체적이고 명확한 지시
- 명령 배경을 설명
- 원하는 결과를 예시로 설명
- 단계별 가이드 제시
- 제약사항 설명
- 결과의 작성 형식을 구체적으로 명시
- ChatGPT가 스스로 생각하며 일할 수 있도록 지시
여기에 더해 ChatGPT와 관련해서는 일반적으로 잘 알려진 팁이 더 있는데요. 함께 살펴볼까요?
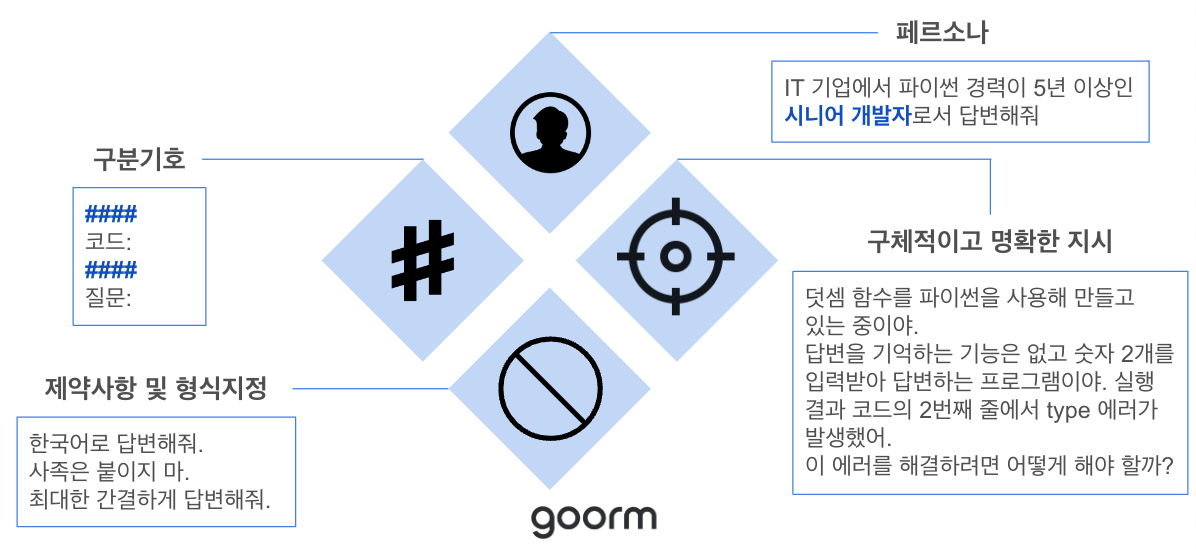
페르소나
페르소나(Persona)는 고대 그리스 가면극에서 배우들이 썼다가 벗었다 하는 가면을 말합니다. 사람(Person)과 인격/성격(Personality)의 어원이 페르소나인데요. 일반적으로는 “이미지 관리를 위해 쓰는 가면”을 의미합니다. LLM에서는 LLM에게 직접 역할을 부여하는 것을 뜻하죠.
LLM에게 번역을 시킬 때 “번역해줘”라고만 하는 게 아니라 “너는 이제부터 번역가고, 한국어를 영어로 번역하는 데 능통해”라고 역할을 주고 번역할 문장을 주는 것입니다. 이렇게 하면 “번역해줘”보다 번역 품질이 더 나아집니다. 실제로 역할을 부여하는 것은 LLM 확률 계산에 꽤 큰 영향을 주거든요.
구분 기호
프롬프트가 길어 명령과 질문이 혼재되면 사람도 맥락을 읽기 어려울 수 있습니다. LLM도 명령 일부를 빼먹거나 맥락을 잘못 파악해서 잘못된 결과를 낼 수 있죠.
이럴 때에는 일종의 구분 기호, 예를 들면 # 혹은 /같은 기호를 사용해 해당 내용이 맥락에 해당되는 내용인지, 명령인지, 질문인지를 구분하면 좋습니다. LLM이 명령과 질문, 내용을 더 명확히 구분하고 이해할 수 있거든요.
제약 사항 및 형식 지정
이는 결괏값과 관련이 있습니다. “결과값을 숫자로 줘” 또는 “한국어로 답해줘”처럼 결괏값의 제약 사항을 먼저 제시하면 LLM이 확률을 계산할 때 제약 조건을 지켜 답변합니다.
구체적이고 명확한 지시
이는 페르소나, 구분 기호, 제약 사항과 비슷합니다. 거의 같은 내용이죠. 자연어에는 동의어도 있고 반의어뿐 아니라 역설적 표현도 많습니다. 이런 것은 LLM이 잘 이해하지 못할 수 있습니다. 결과가 나쁜데, 좋다고 반어법으로 쓰면 사람도 잘못 이해할 수 있죠! 따라서 프롬프트를 작성할 때에는 최대한 구체적으로 명확하게 지시해야 원하는 결과를 얻을 수 있습니다.
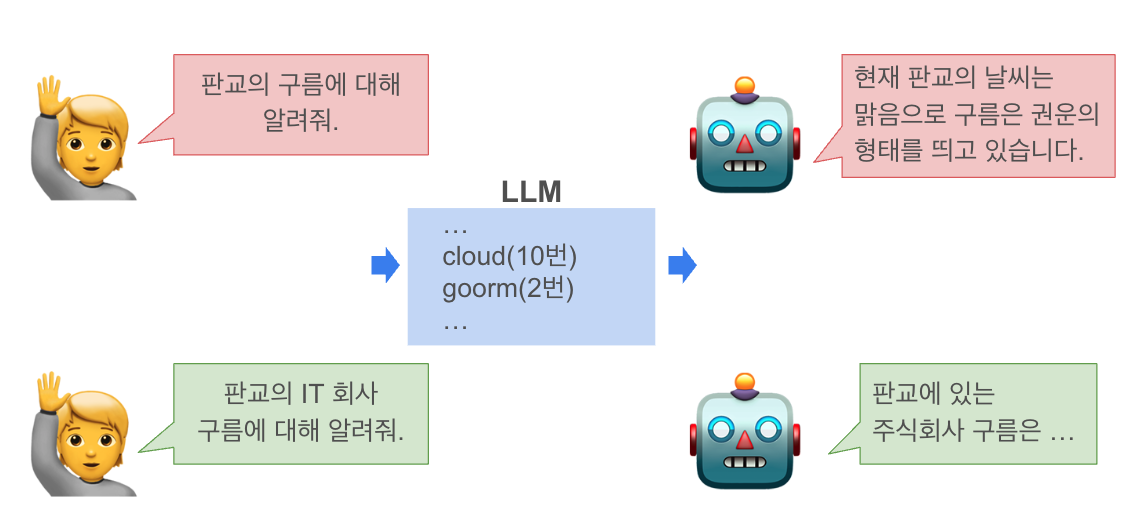
예컨대 LLM 학습 데이터셋에 하늘에 떠다니는 구름(cloud)이 10번, 주식회사 구름(goorm)이 2번 있다고 가정해 봅시다. LLM에게 아무런 배경 지식 없이 “판교 구름에 대해 알려줘”라고 질문하면 LLM는 회사 구름이 아니라 하늘의 구름으로 답할 확률이 높습니다. “판교 IT 회사인 구름”처럼 구체적으로 정보를 줘야 회사 구름에 대해 올바르게 답하겠죠?
다음 프롬프트도 살펴볼까요? 코드에 에러가 있어 LLM에게 오류를 수정해 달라고 요청하는 프롬프트네요. 그럼 배운 팁을 적용해 질의해 볼까요?
def sum(a: str, b: int) -> int:
return a - b
이 코드의 에러를 해결해줘.경력이 일정 이상되는 시니어 개발자로서 답해줘. 실제 코드와 질문은 ###으로 구분하고, 제약사항과 형식을 명시하고, 해당 코드가 무엇을 하는 코드고 어디에서 어떤 에러가 발생했는지를 구체적이고 명확하게 지시합니다.
다음과 같이 질의하면 더 좋은, 원하는 답변을 얻을 수 있겠죠?
### 코드
def sum(a: str, b: int) -> int:
return a - b
### 명령
너는 지금부터 20년차 시니어 개발자야. 파이썬 언어에 정통해.
코드 2번째 줄에서 문자열 a를 정수 b로 빼기 때문에 타입 불일치로 ㅁㅁㅁ 에러가 발생해. 이 코드의 에러를 해결해줘.대표적인 프롬프트 엔지니어링 기법들
지금부터는 일반적인 프롬프트 엔지니어링 기법들을 최대한 쉽게 설명하겠습니다. 차근차근 알아보기로 해요.
1. Few-Shot
Few-Shot은 단어 의미대로 ‘몇 번의 시도’, ‘몇 개를 던진다’라고 할 수 있는데요. 프롬프트에 약간의 예제를 추가해 결과에 영향을 끼치는 기법입니다.

그림을 볼까요? 별다른 명령 없이 mul 2, 1:2처럼 예시를 나열했습니다. 이것이 Few-Shot 기법입니다. Few-Shot 외에는 아무런 정보를 주지 않았지만, 챗GPT는 mul 5, 2: 다음에 올 숫자가 10이라고 답했습니다.
좀 더 복잡한 예시를 살펴보기로 해요.

하나의 집합을 제시하고 “홀수의 합은 짝수입니다”라고 주어줬을 때 챗GPT는 어떤 대답을 할지 우리는 알 수 없습니다. 우리가 원하는 답을 할수도, 똑같은 말을 반복할 수도 있죠.
만약 Few-Shot 기법을 써서 “A:답은 거짓입니다”라고까지 예시를 주면, 예시만으로도 우리가 원하는 답변의 형식으로 답을 할 가능성이 높아지게 됩니다.
그런데, 올바른 답변인가요? 홀수의 합은 짝수라고 제시했는데, 홀수(15, 5, 13, 7, 1)를 다 더해도 짝수가 되지는 않습니다. 답은 홀수죠! 답변이 틀렸네요.
챗GPT는 논리까지는 파악하지 못하고 이렇게 대답해야 된다는 형식만 이해했군요. 그렇다면 우리가 원하는 정확한 답을 얻으려면 어떻게 해야 할까요?
2. CoT(Chain of Thought)
이럴 때 필요한 것이 바로 Chain of Thought, 줄여서 CoT라고 부르는 ‘생각 사슬 기법’입니다.
생각 사슬 기법은 질문을 더 작고 논리적인 부분으로 나눠 질의하는 기법입니다. 이 질문을 해결하려면 이런 이런 과정을 거쳐 이런 답이 나온다고 상세하게 알려주고, LLM이 그 과정을 따라하게 하는 방법입니다.
문제 해결 과정을 하나하나 거치면서 문제를 풀기 때문에 올바른 답을 할 가능성이 높은 거죠!
CoT 기법으로는 Few-Shot과 Zero-Shot이 있습니다. Zero-shot으로 유명한 프롬프트가 ‘Let’s think step by step’입니다. 프롬프트 마지막에 “차근차근 순서대로 생각해봐”라는 말 한마디만 붙여도 LLM은 그냥 답변을 하는 것이 아니라 주어진 프롬프트를 하나하나를 분석해 답을 하게 됩니다.
이를 제대로 사용하려면 Few-Shot을 통해 CoT 기법을 적용해야 합니다.
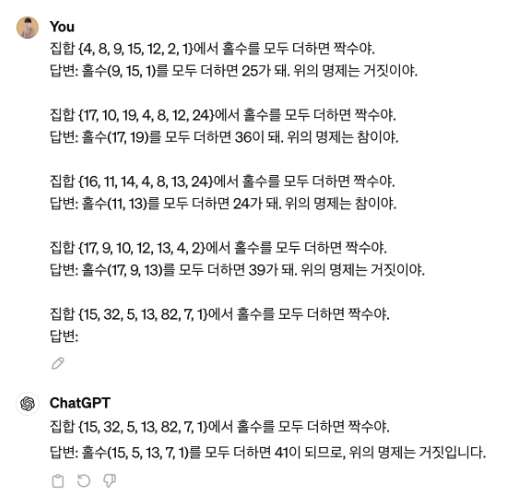
어려워보이나요? 사실 엄청 간단합니다. 앞 예제에서는 잘못된 답을 했었죠. CoT 기법은 홀수만 찾아 모두 더하면 얼마고, 이게 홀수 또는 짝수이니 명제가 참인지 거짓인지 구분하게 유도합니다.
그러자, 챗GPT는 홀수 15, 5, 13, 7, 1을 더하면 41이므로 위의 명제는 거짓이라고 정답을 맞췄네요.
그런데, CoT 기법은 완벽하지 않습니다. 어쩌다 한 번씩 틀린 답을 하기도 하죠. 여기서 한 가지 고민을 해야 합니다. Few-Shot을 4개만 주어줬는데 이걸 30개, 40개까지 늘릴지, 아니면 다른 방법을 쓸지를 말이죠. 예시를 더 늘리기에는 비용이 너무 커질 수 있으니 다른 방법을 찾아보는 게 좋겠네요.
3. Self-Consistency(SC)
다른 해결책의 하나가 Self-Consistency(SC)입니다. 만약 ChatGPT가 정답을 맞출 확률이 90%, 틀릴 확률이 10%라면, 답변 10개를 얻고 더 많이 나온 답을 채택하는 기법입니다. CoT를 확장한 기법이라고 할 수 있죠.
10번 중에 한번 잘못된 답변을 하면, 한 번에 답변 10개를 얻고 통계를 내면 정답률이 항상 90%가 일 테니, 90%의 답을 선택하면 매번 옳은 답을 할 수 있을지 않을까란 생각에서 나온 기법이죠.

예시는 똑같아요. 아까와 같은 집합이 있고 홀수를 더하면 짝수다. 그리고 “명제는 참이냐”라고 물어봤을 때 이상적인 답변은 “이 명제는 거짓입니다”입니다.
이 질문을 LLM에게 10번하니 딱 한 번만 “이 명제는 참입니다”라고 잘못된 답변을 내놨어요.
만약 이 하나하나가 각각의 서비스라면 10번 중에 한 번은 틀린 거겠지만, 이 10번의 과정이 하나의 서비스였고 10번의 결과를 가지고 통계를 냈을 때 어떤 게 과반수인지 선택해서 결과를 도출한다면, 저희는 서비스가 오류 없이 잘 작동한다고 볼 수 있겠죠. 프롬프트에 이상이 생기지 않는 한요.
4. Tree of Thoughts(ToT)
컴퓨터 공학 전공자라면 자료구조를 배웠을 테니 그림이 익숙하죠? 우선 개념 자체는 너비 우선 탐색과 깊이 우선 탐색 그리고 백트래킹(해를 찾는 도중 해가 아니어서 막히면 되돌아가서 다시 해를 찾는 기법) 개념을 같이 사용을 하는 거예요. 여기서는 어떤 과정을 거쳐 답을 도출하는지만 간단히 살펴보겠습니다.
기본적으로는 생각의 분해, 생각 만들기, 생각 평가 총 세 단계로 나눠집니다.
생각의 분해
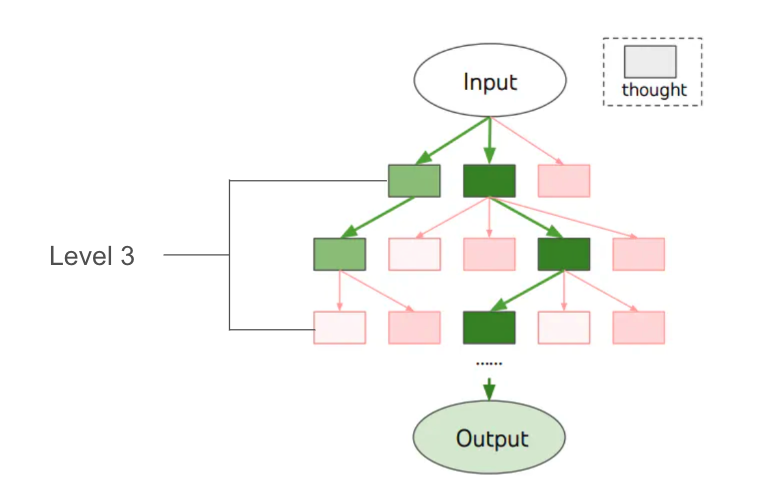
다음 그림에서 노드(박스) 하나하나에 입력과 아웃풋이 있는 ‘생각’이라고 했을 때 몇 단계를 거쳐서 생각을 할 것인지, 이 생각을 만드는 과정을 몇 번 반복할 것인지에 대한 거에요.
개발자라면 트리의 레벨이라고 이해하면 되요. 다음 그림은 세 단계가 있으니까 레벨은 3이겠죠?
생각 만들기
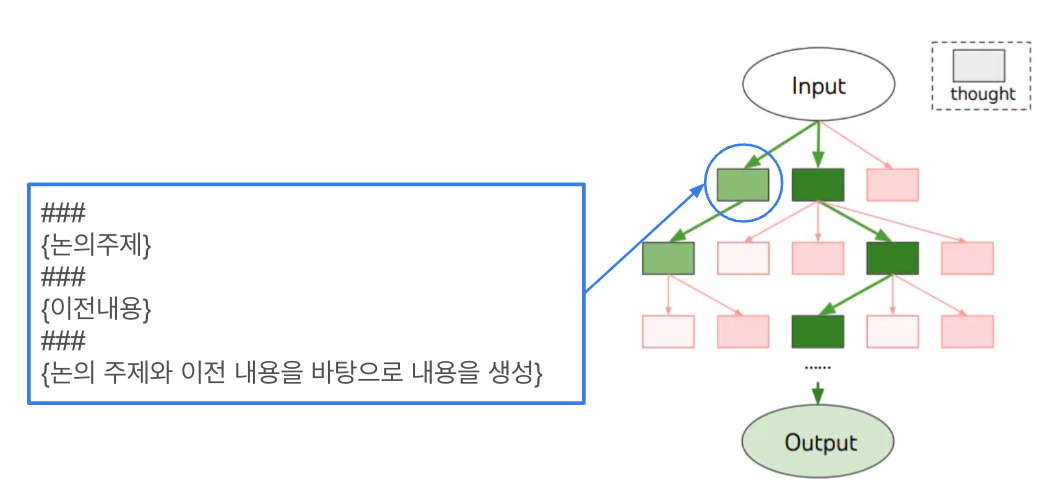
그다음은 ‘생각 만들기’입니다. 노드(박스) 하나하나를 만드는 거에요. 이 생각(노드)에 필요한 것은 노드의 상태와 이전 입력값이겠죠?
예를 들면 “어떤 논의 주제를 갖고 있고 이전 내용은 어떤 게 있었기 때문에 논의 주제와 이전 내용을 바탕으로 이 노드 안에 들어갈 내용을 생성해줘”라고 프롬프트를 넣어 생각(노드)을 계속 만들어가는거에요.
생각 평가 가지치기
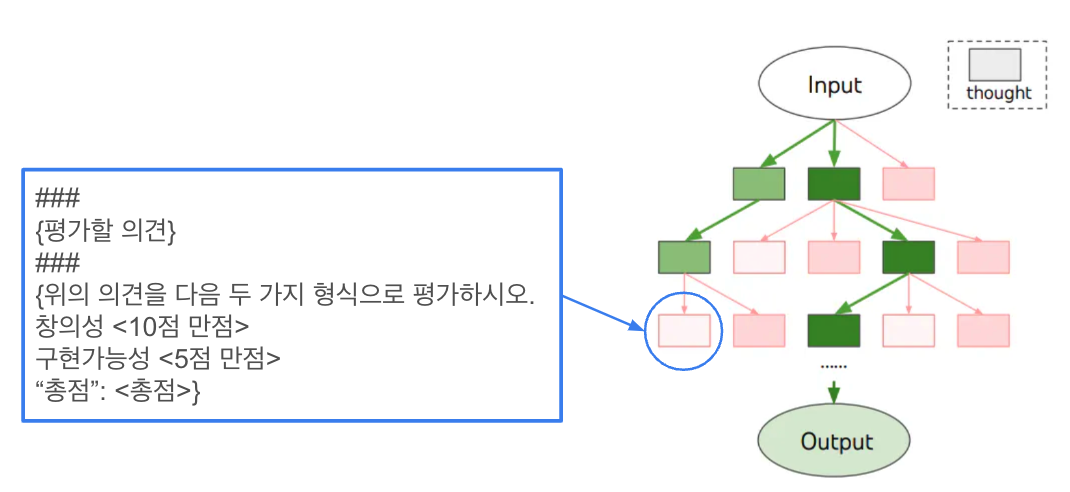
계속 만들다 보면 너무 많겠죠? 그러므로 논의 주제와 이전 내용을 바탕으로 내용을 생성했을 때 결과값이 안 좋은 생각(노드)는 과감히 없애야 합니다.
이것이 바로 ‘생각 평가 가지치기’예요. 그래서 ‘평가할 의견’에 이전 각각의 생각(노드)의 내용을 넣고 LLM에게 우리가 원하는 항목의 점수를 매기고 그 점수의 총점을 내서 생각(노드)마다의 순위를 매기고, 상위 생각(노드)만 남기고 나머지 생각을 다 정리하는 거예요.
이걸 원하는 ‘레벨’만큼 반복해서 결과를 얻는 게 ToT예요. 그런데 ToT에 대해서는 이렇게 글로만 설명하고 프롬프트 예시를 보여드리지 않았는데요. 그만큼 꽤 많이 생각해야 하는 복잡한 작업이기 때문이에요.
5. ReAct(Reasoning + Acting)
다음은 ReAct입니다. ReAct는 Reasoning와 Acting을 합친 방법인데, 인간의 행동 양식에서 영감을 얻은 엔지니어링 기법이에요.
인간은 일단 생각하고 그다음에 행동을 하고, 그 행동으로 얻은 결과를 다시 생각을 원천으로 삼고, 다시 어떻게 행동할지를 생각하고 행동한다는 점에 착안한 건데요.
프롬프트에 추론, 계획/생성, 행동, 관찰(지각)로 구성을 합니다.
- 추론은 현재 상황에 대한 추론이에요.
- 행동은 이 추론을 바탕으로 어떤 행동을 할지 검색을 할지, 조회할지, 종료할지, 혹은 우리가 원하는 각 기능을 어떻게 실행할지에 대한 행동을 말해요.
- 관찰은 앞서 행동으로 얻은 정보를 다음 추론의 근거로 삼을 수 있게 관찰하는 걸 말해요.
이 세 가지를 하나의 세트로 묶어 문제가 해결될 때까지 반복하는 거예요.
예컨대 “대한민국 축구 국가대표 주장이 현재 속한 축구 클럽의 주전 골키퍼는 누구야”라고 질문한다고 가정해봐요.
LLM이 2020년까지의 데이터만 학습을 한 상태라면, 2024년의 국가대표 주장은 누구인지 뿐 아니라, 어디 클럽 소속인지도 모를 거예요. 우리의 물음에 올바른 답을 할 수 없겠죠?
ReAct 기법을 사용하면 이런 과정을 거쳐 답을 합니다.
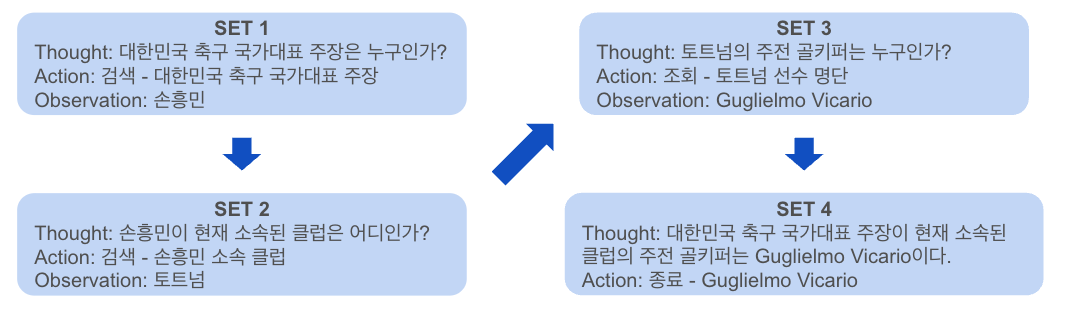
세트 1에서는 이 질문을 쪼개서 대한민국 축구 국가대표 축구 국가대표 주장이 누군가를 먼저 생각해요. 그다음 액션으로 대한민국 축구 국가대표 주장을 검색해요. 검색 결과, ‘손흥민’ 이란 값을 관찰(Observation) 해냈어요.
세트 2에서는 손흥민이 현재 소속된 클럽은 어디인지를 액션(검색)해서 소속 클럽을 찾아요.
이처럼 세트를 반복해서 결국 토트넘 선수 명단을 조회해 주전 골키퍼인 ‘비카리오’란 선수의 이름을 찾아내요.
이런 과정을 통해 LLM이 알지 못하는 정보도 액션을 적절히 넣어줌으로써 원하는 결과를 얻을 수 있는 거예요.
프롬프트 엔지니어링에 은총알은 없다
지금까지 LLM과 프롬프트 엔지니어링의 기초를 살펴봤어요. LLM은 결코 아이언맨 영화에 나오는 자비스 같은 만능 AI 모델은 아니에요. LLM은 그저 확률 모델, 언어 확률 모델이라는 걸 이제 알거예요.
그렇기 때문에 아직은 추론, 수리, 논리력과 같은 부분이 약해요. 이런 약점을 여러 기법으로 보완했기 때문에 좋아 보이는 것 뿐이죠.
프롬프트 엔지니어링의 역사는 매우 짧아요. 인기 있는 프롬프트 엔지니어링 논문도 오래되어 봤자 2020년쯤인 경우가 많아요. 대부분의 프롬프트 엔지니어링 논문은 챗GPT와 같은 유명 모델에 맞춰 작성됐기 때문에 차후 다른 모델이 나오거나 하면, 현재 작성한 대부분의 프롬프트가 무용지물이 될 수도 있어요.
개발 분야에는 은탄환은 없다(There is no silver bullet)는 말이 있습니다. 프레드 브룩스가 쓴 소프트웨어 공학 논문에 처음 쓰인 말인데요. 소프트웨어 개발의 복잡성을 한번에 해소할 마법 같은 솔루션(은탄환)은 없다는 거예요.
프롬프트 엔지니어링도 마찬가지입니다. 이렇게 하면 결과가 잘 나온다. 이 방법이 정답이다 그런 것은 없습니다. 여러분 스스로 여러 기법을 사용해 보고, 보완하고 시도하는 과정을 반복해야 하죠.
그 여정에 작은 도움이 되길 바라며 글을 마칩니다.



